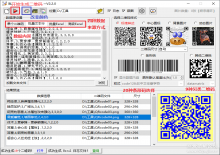
源码介绍
批量下载方法
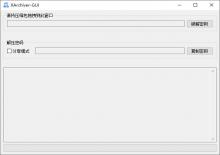
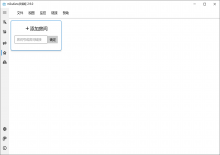
1、下载软件,打开, 输入模板地址即可下载。

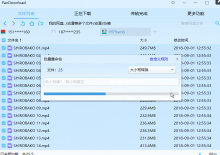
第2次下载会跳过已经下载过的文章,再用这个html批量转pdf工具 https://wdzzz.lanzoue.com/iSpV90fbtpqh
还生成了一个文章列表excel,包含文章日期,文章标题,文章链接和文章封面。

部分代码如下:
def down(begin,count):
url2=url.replace('#wechat_redirect','')
url_home = f'{url2}&begin={begin}&count={count}&action=appmsg_list&f=json&r=0.26146868035616433&appmsg_token='
res = requests.post(url_home,headers=headers,verify=False).json()
for i in res['appmsg_list']:
if html.unescape(i['link']) in urls:
print('已经下载过文章:'+html.unescape(i['link']))
continue
data = requests.get(i['link'],headers=headers,verify=False)
content = data.text.replace('data-src', 'src')
try:
date = time.strftime('%Y-%m-%d', time.localtime(int(i['sendtime'])))
title = i['title']
print('正在下载文章:',title,i['link'])
with open(date+'_'+trimName(title)+'.html', 'w', encoding='utf-8') as f:
f.write(content)
except Exception as e:
with open(str(randint(1,10))+'.html', 'w', encoding='utf-8') as f:
f.write(content)
print('错误信息:',e)
with open(fname, 'a+', encoding=encoding) as f2:
f2.write(date+','+title + ','+i['author'] + ','+i['digest'] + ','+html.unescape(i['link'])+ ','+i['cover']+'\n')
源码下载地址
下载即代表您已阅读并同意以下条款:
1、所有资源仅供学习与参考,请学习后自行删除。本站不提供任何技术支持。
2、本站不保证资源的完整性、可用性、安全性。(单独付费源码除外)
3、如有侵犯您的版权,请及时联系我们,我们将下架处理。
1、所有资源仅供学习与参考,请学习后自行删除。本站不提供任何技术支持。
2、本站不保证资源的完整性、可用性、安全性。(单独付费源码除外)
3、如有侵犯您的版权,请及时联系我们,我们将下架处理。